개발 환경 : pycharm-community-2020.2 (무료 에디션)
Anaconda, python3.7, Windows 10
세계항공 여행승객 수의 증가 데이터를 활용해 다음 달의 승객 수를 예측한다.
1. 패키지 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import model_selection
from keras import models, layers
from keraspp import skeras- pandas 는 엑셀같이 시트로 관리되는 데이터를 처리하는 패키지
- numpy 는 숫자로 된 데이터 행렬을 처리하는 패키지
- model_selection() 은 데이터를 학습과 검증용으로 나누는 함수
- skeras 는 학습 결과를 그래프로 그려주는 기능을 제공하는 서브패키지
2. 학습하고 평가하기
Machine() 클래스를 이용해 machine 인스턴스를 생성 -> 학습 및 성능 평가를 진행
def main():
machine = Machine()
machine.run(epochs=400)
Machine 클래스는 시계열 LSTM을 학습하고 평가하는 플랫폼이다. -> 초기화 함수와 실행 함수를 만든다.
초기화 함수부터 !
class Machine():
def __init__(self): #초기화 함수
self.data = Dataset()
shape = self.data.X.shape[1:] #입력계층크기를 shape변수에 정의
self.model = rnn_model(shape)- 데이터 생성에 사용할 Dataset() 클래스의 인스턴스를 만든다. 이 인스턴스는 self.data 에 저장한다.
- 입력 데이터의 샘플 수는 shape에 포함될 필요가 없어서, shape = (12, 1) 이 된다.
- rnn_model(shape) 함수로 LSTM 모델을 만들어 self.model 에 저장한다.
- 이렇게 만들어진 self.data 와 self.model 은 머신을 실행하면 사용된다.
다음으로 머신을 실행하는(run) 멤버 함수를 만든다 !
m=self.model : m으로 선언해서 모델이 사용됨을 알린다.
def run(self, epochs=400):
d = self.data
X_train, X_test, y_train, y_test = d.X_train, d.X_test, d.y_train, d.y_test
X, y = d.X, d.y
m = self.model
h = m.fit(X_train, y_train, epochs=epochs, validation_data=[X_test, y_test], verbose=0) #학습
그래프 출력 결과
skeras.plot_loss(h) # 학습 곡선을 그리는 함수
plt.title('History of training')
plt.show()

학습이 완료된 후 검증 데이터를 이용한 손실 측정은 다음과 같다.
yp = m.predict(X_test)
print('Loss:', m.evaluate(X_test, y_test))
결과 : 0.0013 으로 매우 적다.

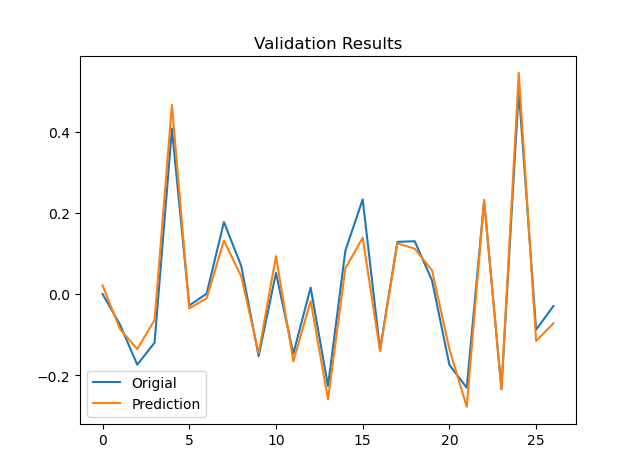
검증 데이터로 예측값과 실제값을 비교한 그래프
그래프를 보면 선이 거의 일치하는 것으로 보아 대부분 예측이 잘 되었다고 할 수 있다.
plt.plot(yp, label='Origial')
plt.plot(y_test, label='Prediction')
plt.legend(loc=0)
plt.title('Validation Results')
plt.show()
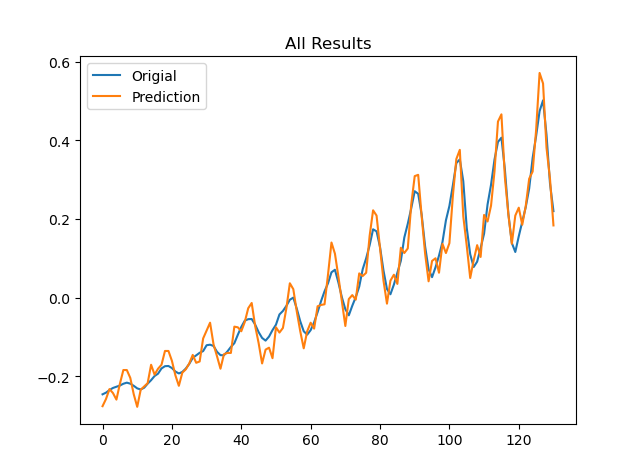
이제 학습 데이터와 평가 데이터의 결과를 합칠 것이다.
전체적으로 학습이 얼마나 잘 되었는지 확인하기 위해, 학습 데이터(파란)와 예측 데이터(주황)의 결과를 비교해본다.
예측이 원래 데이터(파란)와 비교했을 때 잘 되었음을 확인할 수 있다.
yp = m.predict(X) # 전체데이터에 대해 예측
plt.plot(yp, label='Origial')
plt.plot(y, label='Prediction')
plt.legend(loc=0)
plt.title('All Results')
plt.show()
3. LSTM 시계열 회귀 모델링
모델의 구성 : 입력(12, 1) -> [ LSTM (10) ] -> 출력(1)
케라스 라이브러리에서 제공하는 Model을 이용해 모델을 만든다.
- 입력계층(m_x)에 제공되는 데이터 모양은 shape에 따라 정의된다.
- LSTM 계층과 출력 계층을 설정한다.
- 출력 계층의 노드 수는 이진판별이니까 1로 정의한다.
def rnn_model(shape):
m_x = layers.Input(shape=shape) # X.shape[1:]
m_h = layers.LSTM(10)(m_x) # 노드수 10
m_y = layers.Dense(1)(m_h)
m = models.Model(m_x, m_y)
모델을 구성했으니 컴파일하고 어떻게 만들어졌는지 요약을 해본다.
m.compile('adam', 'mean_squared_error')
m.summary()화면 요약

- 입력 계층은 12개의 시간열과 1개의 특징점으로 구성되어 있다.
- LSTM은 10개의 노드로 구성되어 있고 이를 처리하는 내부 파라미터가 480개이다.
- LSTM과 출력 계층 사이에 적용되는 가중치 수는 11개이다. -> 10개는 입력값에 대한 가중치, 1개는 평균값을 조절하는 가중치
4. 데이터 불러오기
클래스를 선언하고 초기화 함수를 정의한다.
- D=12 : 시계열 길이
- 학습데이터와 평가데이터를 나눈다.
class Dataset:
def __init__(self, fname='international-airline-passengers.csv', D=12):
data_dn = load_data(fname=fname)
X, y = get_Xy(data_dn, D=D)
X_train, X_test, y_train, y_test
= model_selection.train_test_split(X, y, test_size=0.2, random_state=42)
클래스를 이용할 때 결과를 볼 수 있도록 결과를 멤버 함수에 저장
self.X, self.y = X, y
self.X_train, self.X_test, self.y_train, self.y_test = X_train, X_test, y_train, y_test
로드 데이터 함수 구현
- 승객수에 해당하는 1열만 불러온다.
- 데이터프레임 구조에서 넘파이 행렬로 바꾸고, 넘파이 행렬을 1차원 모양으로 바꾼다.
def load_data(fname='international-airline-passengers.csv'):
dataset = pd.read_csv(fname, usecols=[1], engine='python', skipfooter=3)
data = dataset.values.reshape(-1)
plt.plot(data)
plt.xlabel('Time');
plt.ylabel('#Passengers')
plt.title('Original Data')
plt.show()
불러온 데이터 확인
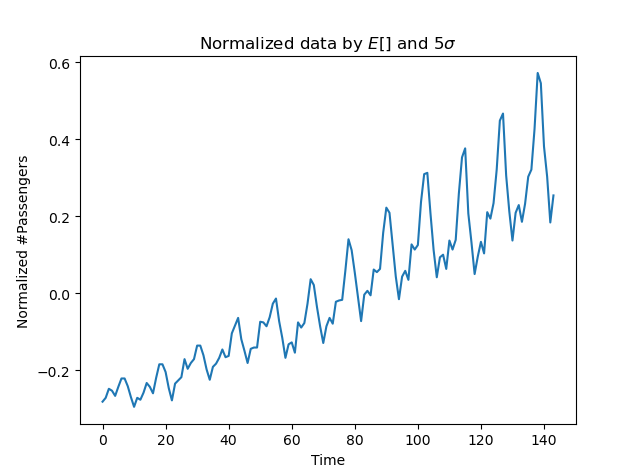
이 데이터는 'LSTM 인공신경망 기능'을 충분히 활용할 수 없어서 데이터 평균화를 진행해야 한다.
- LSTM 인공신경망 기능 : -1과 1사이의 값으로 활성화를 수행

평준화된 월간 항공기 여행자 수 그래프
- 표준화 방법은 평균을 제거하고, 분산을 단위 값으로(time, 월) 만드는 기법이다.
- 여기서는 분산의 제곱근을 5로 나눈다.
# data normalize
data_dn = (data - np.mean(data)) / np.std(data) / 5
plt.plot(data_dn)
plt.xlabel('Time');
plt.ylabel('Normalized #Passengers')
plt.title('Normalized data by $E[]$ and $5\sigma$')
plt.show()
다음으로 받아오는(get) 함수를 구현
D개월 간의 승객수 변화를 통해 그 다음 달의 승객 수를 예측할 수 있는지 알아보는 데이터셋을 만들었다.
- 이 함수는. D 샘플 만큼의 시계열 데이터를 한칸씩 옮겨가면서 시계열 벡터로 만든다.
- D+1 샘플의 값을 레이블로 했다.
def get_Xy(data, D=12):
# make X and y
X_l = []
y_l = []
N = len(data)
assert N > D, "N should be larger than D, where N is len(data)"
for ii in range(N - D - 1):
X_l.append(data[ii:ii + D])
y_l.append(data[ii + D])
X = np.array(X_l)
X = X.reshape(X.shape[0], X.shape[1], 1)
y = np.array(y_l)
print(X.shape, y.shape)
return X, y
전체 코드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import model_selection
from keras import models, layers
from keraspp import skeras
def main():
machine = Machine()
machine.run(epochs=400)
class Machine():
def __init__(self):
self.data = Dataset()
shape = self.data.X.shape[1:]
self.model = rnn_model(shape)
def run(self, epochs=400):
d = self.data
X_train, X_test, y_train, y_test = d.X_train, d.X_test, d.y_train, d.y_test
X, y = d.X, d.y
m = self.model
h = m.fit(X_train, y_train, epochs=epochs, validation_data=[X_test, y_test], verbose=0)
skeras.plot_loss(h)
plt.title('History of training')
plt.show()
yp = m.predict(X_test)
print('Loss:', m.evaluate(X_test, y_test))
plt.plot(yp, label='Origial')
plt.plot(y_test, label='Prediction')
plt.legend(loc=0)
plt.title('Validation Results')
plt.show()
yp = m.predict(X)
plt.plot(yp, label='Origial')
plt.plot(y, label='Prediction')
plt.legend(loc=0)
plt.title('All Results')
plt.show()
def rnn_model(shape):
m_x = layers.Input(shape=shape) # X.shape[1:]
m_h = layers.LSTM(10)(m_x)
m_y = layers.Dense(1)(m_h)
m = models.Model(m_x, m_y)
m.compile('adam', 'mean_squared_error')
m.summary()
return m
class Dataset:
def __init__(self, fname='international-airline-passengers.csv', D=12):
data_dn = load_data(fname=fname)
X, y = get_Xy(data_dn, D=D)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.2, random_state=42)
self.X, self.y = X, y
self.X_train, self.X_test, self.y_train, self.y_test = X_train, X_test, y_train, y_test
def load_data(fname='international-airline-passengers.csv'):
dataset = pd.read_csv(fname, usecols=[1], engine='python', skipfooter=3)
data = dataset.values.reshape(-1)
plt.plot(data)
plt.xlabel('Time');
plt.ylabel('#Passengers')
plt.title('Original Data')
plt.show()
# data normalize
data_dn = (data - np.mean(data)) / np.std(data) / 5
plt.plot(data_dn)
plt.xlabel('Time');
plt.ylabel('Normalized #Passengers')
plt.title('Normalized data by $E[]$ and $5\sigma$')
plt.show()
return data_dn
def get_Xy(data, D=12):
# make X and y
X_l = []
y_l = []
N = len(data)
assert N > D, "N should be larger than D, where N is len(data)"
for ii in range(N - D - 1):
X_l.append(data[ii:ii + D])
y_l.append(data[ii + D])
X = np.array(X_l)
X = X.reshape(X.shape[0], X.shape[1], 1)
y = np.array(y_l)
print(X.shape, y.shape)
return X, y
if __name__ == '__main__':
main()
마무리. RNN은 문장, 음성 등과 같은 시계열 데이터 처리에 적합한 인공신경망이다. - 음성 인식, 문장 번역에 이용
기존 RNN의 한계를 극복하고자 제안된 LSTM은 망각, 입력, 출력 게이팅을 이용하여 우수한 시계열 데이터 처리 성능을 보이고 있다.
참고 : 3분 딥러닝 케라스맛 (김성진 지음)
데이터셋 : international-airline-passengers.csv
'Keras Deep Learning' 카테고리의 다른 글
| [미니 프로젝트] 와인 품질 예측 (0) | 2020.12.14 |
|---|---|
| 생성적 대립 신경망, GAN의 원리 (0) | 2020.10.30 |
| RNN(순환신경망) 문장을 판별하는 LSTM 케라스로 구현 실습 (0) | 2020.08.25 |
| 컬러 이미지를 분류하는 DNN 구현 실습 (0) | 2020.08.20 |
| 필기체를 분류하는 DNN 구현 실습 (0) | 2020.08.19 |


